Nuxt
Nuxt.js的ssr服务端渲染原理
Nuxt.js 的 SSR(服务端渲染)原理是一个非常核心且有趣的话题。它并不是简单的“在服务器上跑 Vue”,而是一套完整的、精心设计的架构。
简单来说,它的核心原理是:“首屏在服务器提前渲染成 HTML,之后在客户端‘激活’为 SPA”。
下面我们分步拆解这个过程的原理、优势和关键实现。
一、核心目标:解决什么問題?
- SEO(搜索引擎优化):传统 SPA(单页应用)返回的是一个空的 HTML 壳,内容由 JavaScript 动态填充。搜索引擎爬虫可能无法等待和执行 JS,导致无法收录内容。SSR 直接返回渲染好的完整 HTML,利于爬虫抓取。
- 更快的内容到达时间:用户浏览器无需等待所有 JavaScript 下载和执行完毕才能看到内容。服务器直接返回了渲染好的 HTML,首屏内容可以立即展示,感知性能极大提升。
二、Nuxt.js SSR 的核心工作流程
Nuxt.js 的 SSR 过程可以清晰地分为两个阶段:服务端渲染和客户端激活。下图展示了从用户请求到页面可交互的完整生命周期:
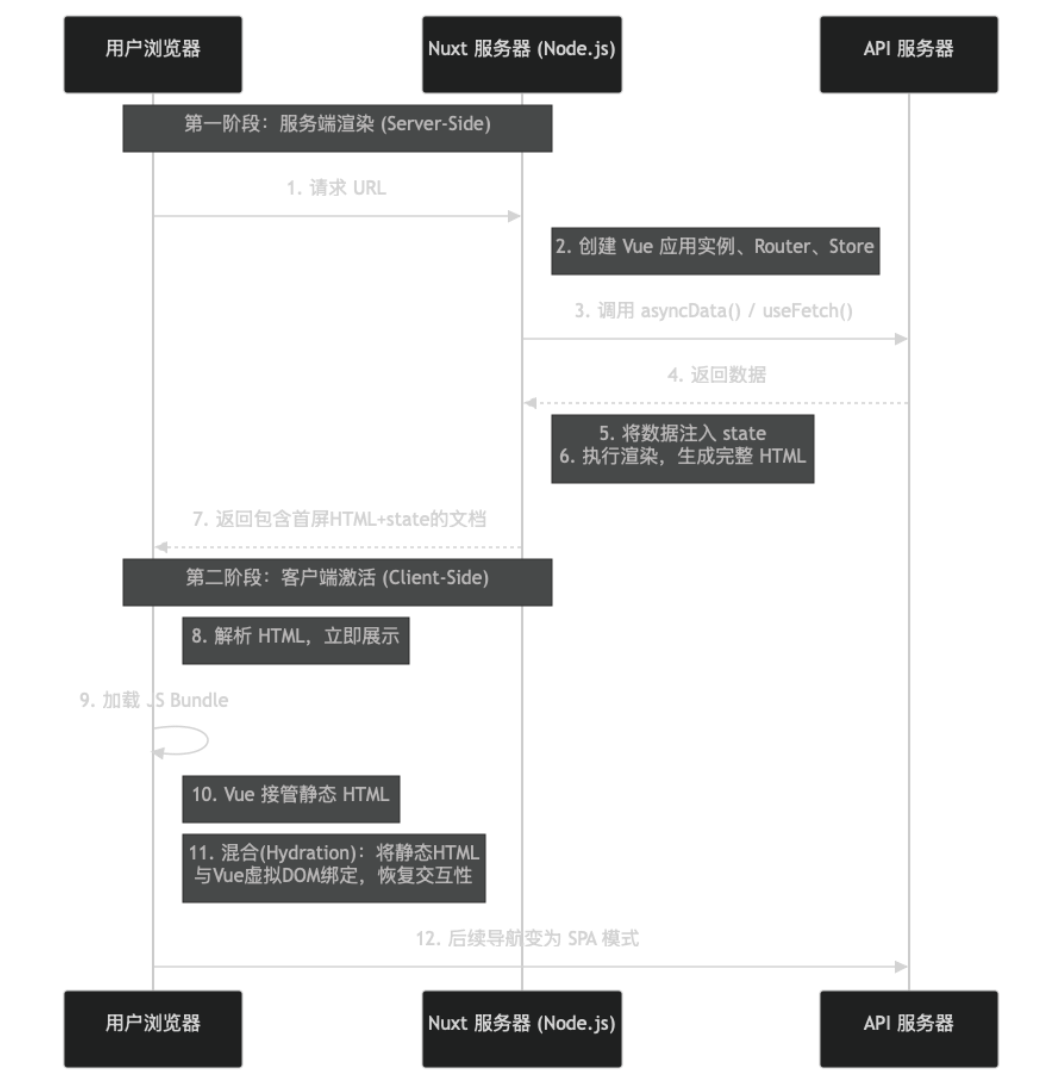
第一阶段:服务端渲染(Server-Side)
这个过程发生在 Nuxt 服务器(一个 Node.js 服务器)上。
- 接收请求:用户浏览器请求一个 URL,请求到达 Nuxt 服务器。
- 创建应用实例:Nuxt 服务器为这次请求创建一个全新的 Vue 应用实例、Router 和 Store。这是关键,确保了每个请求的隔离性。
- 路由匹配:根据请求的 URL,Nuxt Router 确定要渲染哪个页面组件(如
pages/about.vue)。 - 数据预取:Nuxt 会调用页面组件中定义的异步数据获取方法(如
asyncData、useAsyncData、useFetch)。这些方法会在服务端执行。- 服务器会等待这些异步操作完成,再去渲染组件。这确保了渲染出的 HTML 是包含数据的。
- 渲染 HTML:
- 将获取到的数据注入到 Vuex Store 或组件状态中。
- 调用 Vue 的
vue-server-renderer(Vue 2)或@vue/server-renderer(Vue 3)的renderToString()函数。 - 这个函数会运行 Vue 组件,但它不是在浏览器中创建真实 DOM,而是在内存中生成一个完整的 HTML 字符串。
- 构建最终文档:Nuxt 将这个 HTML 字符串插入到HTML模板(
app.html)中。同时,将预取的数据序列化后内联到 HTML 中(通常是在一个<script>标签里,如window.__NUXT__ = {...}),这个过程称为 状态脱水。 - 响应:将这个完整的、包含数据和内容的 HTML 文档发送给客户端。
第二阶段:客户端激活(Client-Side Hydration)
这个过程发生在用户浏览器上。
- 静态内容展示:浏览器收到服务器返回的 HTML 后,无需等待任何 JavaScript,就能立即解析和显示页面内容。这是首屏速度快的根本原因。
- 加载资源:浏览器开始加载页面中引用的 JavaScript 和 CSS 资源(Nuxt 打包好的客户端 bundle)。
- Vue 接管(Hydration -“混合”):这是最精妙的一步。
- 客户端的 Vue 应用也会被创建和初始化。
- Vue 不会像传统 SPA 那样清空 DOM 再重新渲染。相反,它会将虚拟 DOM 与服务器渲染好的现有静态 HTML 结构进行“混合”。
- 它会将事件监听器、Vue 的响应式系统等“激活”到这些静态元素上,使其变成一个完全交互式的 Vue 应用。
- 变为 SPA:激活完成后,应用就切换到了正常的 SPA 模式。后续的页面导航不会再向服务器请求完整的 HTML,而是由客户端 Router 管理,只获取必要的数据,实现无刷新跳转。
三、Nuxt.js 实现 SSR 的关键技术点
- 双入口构建(Dual Entry Points):
- Nuxt 使用 Webpack/Vite 分别打包两个版本的代码:
- 服务端 Bundle:用于
renderToString,它知道如何在 Node.js 环境中渲染组件。 - 客户端 Bundle:用于在浏览器中“激活”静态页面并处理后续交互。
- 服务端 Bundle:用于
- 这是通过
webpack的target: 'node'和target: 'web'分别配置实现的。
- Nuxt 使用 Webpack/Vite 分别打包两个版本的代码:
- 数据预取与状态同步:
- 服务端获取的数据必须安全地传递到客户端,否则客户端 Vue 在初始化时没有数据,会导致虚拟 DOM 与服务器渲染的 HTML 不匹配,激活失败。
- Nuxt 通过
window.__NUXT__对象将数据从服务器“脱水”到客户端“补水”,保证两端状态一致。
- 生命周期:
- 在 SSR 过程中,只有**
**beforeCreate**和**created****这两个生命周期钩子会在服务端执行。 mounted、beforeMount等只在客户端执行。因此,在****created**中操作**window****或 DOM 会报错。
- 在 SSR 过程中,只有**
四、Universal Mode (同构渲染)
Nuxt.js 的 SSR 通常被称为 “Universal”应用或**“同构”应用**。
- 同构代码:同一份 Vue 组件代码(
.vue文件)既可以在服务器上运行(用于首屏生成 HTML),也可以在客户端运行(用于激活和后续交互)。 - 优势:开发者只需写一套代码,Nuxt 负责处理双端的构建和渲染协调,开发体验非常流畅。
总结
Nuxt.js 的 SSR 原理可以概括为:
- 服务端:为每个请求即时创建 Vue 应用,预先获取数据,渲染出包含内容的 HTML 字符串,并将数据状态一同返回。
- 客户端:快速展示静态内容,然后加载 JS,由 Vue 将静态页面“激活”为可交互的 SPA,最后接管所有后续导航。
它完美地结合了传统服务端渲染首屏快、SEO 好的优势和单页应用用户体验流畅、交互丰富的优势,是现代 Web 应用开发的绝佳选择。
nuxt中调后端接口怎么做,要注意什么?
在 Nuxt.js 中调用后端接口是其核心功能之一,但根据你使用的 API 风格(Composition API 或 Options API)和渲染模式(SSR 或 SPA),做法和注意事项有所不同。
下面将为你提供全面的指南,包括方法、最佳实践和常见陷阱。
一、如何调用后端接口?
Nuxt 3 推荐使用 Composition API,并提供了强大的组合式函数。
1. 使用 useFetch / useAsyncData (Composition API - 首选)
这是 Nuxt 3 中最现代、最推荐的方式,它完美处理了服务端和客户端的数据获取。
基本用法 (**useFetch**):useFetch 是专门为获取数据而设计的语法糖。
1 | <script setup> |
高级用法 (**useAsyncData**** + **$fetch**):**
当你需要更复杂的逻辑时(如多个请求、数据处理),使用 useAsyncData。
1 | <script setup> |
2. 使用 $fetch 直接调用
Nuxt 3 内置了基于 ofetch 的 $fetch 工具,可以在任何地方使用(如事件处理函数中)。
1 | <script setup> |
3. 使用 useLazyFetch / useLazyAsyncData
它们是 useFetch 和 useAsyncData 的变体,lazy: true 是默认行为。不会阻塞导航,适用于非关键数据。
1 | <script setup> |
二、最重要的注意事项
1. 服务端渲染 (SSR) vs 客户端渲染 (CSR) 行为
这是 最核心、最容易出错 的点!
- 默认行为:
useFetch和useAsyncData会在服务端执行。这意味着:- 好处:返回的 HTML 直接包含数据,利于 SEO 和首屏加载。
- 陷阱:不能在它们内部或**
**created****生命周期中使用浏览器API(如window,document,localStorage)。
- 如何控制:
1 | // 选项 1: 强制只在客户端执行 |
2. 处理 CORS (跨域资源共享)
如果你调用的接口不在同一个域下,会遇到 CORS 问题。
- 开发环境:在
nuxt.config.ts中配置代理是最佳实践。
1 | // nuxt.config.ts |
- 然后你在代码中请求
/api/users,开发服务器会将其代理到https://api.example.com/api/users,避免 CORS。 - 生产环境:
- 最佳方案:配置你的反向代理(如 Nginx)来处理跨域请求。
- 备选方案:确保后端 API 正确配置了 CORS 头 (
Access-Control-Allow-Origin等)。
3. 认证和令牌 (Authentication)
如何安全地传递身份验证信息(如 JWT Token)。
- 使用请求拦截器:利用
ofetch的自动全局拦截器。 - 如何安全地传递身份验证信息(如 JWT Token)。
1 | // plugins/api.ts |
4. 错误处理
永远不要假设请求一定会成功。
- 使用 try-catch:
1 | try { |
- 使用
**useFetch**的状态:
1 | <script setup> |
5. 性能优化:避免重复请求
- Key 的妙用:
useAsyncData和useFetch会自动去重具有相同 key 的请求。确保为唯一的数据集提供唯一的 key。
1 | // 如果两个组件使用相同的 key,只会发出一个请求 |
- 缓存:
$fetch默认不会缓存 HTTP 缓存。如果你需要利用 HTTP 缓存,可以在 headers 中设置,或者使用更高级的缓存策略。
三、最佳实践总结
- 首选**
**useFetch**/****useAsyncData**:用于在组件中获取数据,它们能智能处理 SSR 和 hydration。 - 明确数据获取时机:想清楚你需要的数据是应该在服务端获取(SEO 关键)还是客户端获取(用户相关),并用
server: false或useLazyFetch控制。 - 开发环境用代理解决 CORS:在
nuxt.config.ts中配置代理,避免跨域问题。 - 统一处理认证和错误:通过插件创建配置好的
$fetch实例,全局处理 token 和错误。 - 善待你的 API:合理使用 key 去重,避免重复请求;考虑分页、限流和缓存。
遵循这些指南,你就能在 Nuxt 应用中高效、可靠地与后端 API 进行交互。
开发环境需要配置代理是指客户端发起请求的情况下吗?服务端请求应该没有跨域问题吧?
你这个问题问得非常好,直击要害!你的理解完全正确。
是的,你的推理是精准的:
- 服务端(Node.js)发起的请求:没有跨域概念。跨域是浏览器强加的安全策略。Node.js 发请求就像你用
curl或 Postman 一样,可以去任何地方,不存在 CORS 问题。 - 客户端(浏览器)发起的请求:受跨域限制。浏览器会拦截违反同源策略的请求。
因此,“开发环境配置代理” 主要就是为了解决 —— 在客户端发起请求时遇到的跨域问题。
为什么开发环境会有客户端请求?
在 Nuxt 3 的 SSR 模式下,一个页面渲染通常涉及两次数据获取:
- 第一次(服务端请求 - 无 CORS):
- 当用户直接访问页面 URL 时,请求会先到达你的 Nuxt 服务器。
- Nuxt 服务器执行
useFetch或useAsyncData,在服务器环境(Node.js)中向后端 API 发起请求。 - 此时是 服务器对服务器 的通信,没有浏览器参与,所以没有 CORS 问题。
- 服务器拿到数据后,渲染出包含内容的 HTML 并返回给浏览器。
- 第二次(客户端请求 - 有 CORS 风险):
- 浏览器收到 HTML 并展示后,会加载 Nuxt 的客户端 JS Bundle。
- Vue 开始 “激活” (Hydration) 过程。
- 在这个过程中,
useFetch和useAsyncData的代码会在客户端浏览器环境中再次运行,以确保数据状态一致。 - 如果它们的 URL 是绝对路径(如
https://api.example.com/data),那么这次请求就是由浏览器直接发起的,就会触发 CORS 检查。 - 如果后端 API 没有正确配置 CORS 头,浏览器就会拦截这次请求,导致错误。
此外,还有几种常见的纯客户端请求场景:
- 用户交互(如点击按钮)触发的
$fetch请求。 - 在
onMounted钩子中发起的请求。 - 使用
useLazyFetch(它默认在客户端执行)。
总结与最佳实践
| 场景 | 请求发起方 | 是否有 CORS 问题? | 解决方案 |
|---|---|---|---|
| SSR 首屏渲染 | Nuxt Server (Node.js) | 否 | 无需额外配置。但需确保服务器能访问到 API(网络连通性)。 |
| CSR Hydration/交互 | 浏览器 | 是 | 配置开发服务器代理(如下方代码)。这是最推荐的方法。 |
| 生产环境 | 浏览器 | 是 | 配置生产级反向代理(如 Nginx),或确保后端 API 正确设置 CORS 头。 |
nuxt中的$fetch是只能在客户端调用吗?,useFetch和useAsyncData呢?
非常好的问题!这是理解 Nuxt 3 数据获取的关键。它们的执行环境行为是核心区别。
简单直接的答案是:不,**$fetch**** 可以在服务端和客户端调用。而 **useFetch** 和 **useAsyncData** **的行为是智能的,默认在服务端执行。
下面我们来详细拆解这三者的区别。
一、$fetch:双环境通用的请求工具
$fetch 是 Nuxt 3 基于 ofetch 提供的全局工具函数。它本身没有环境限制,你在哪里调用它,它就在哪个环境执行。
- 在服务端(Node.js)调用:它就像一个普通的 Node.js HTTP 客户端(比如
axios),直接向后端发起请求,没有跨域概念。 - 在客户端(浏览器)调用:它的行为类似于原生的
fetch(),但功能更强大(自动处理 JSON、更好的错误处理等),并且受浏览器跨域策略限制。
示例:
1 | // 1. 在组件 setup 中直接调用 - 根据渲染环境决定 |
**$fetch**** 的陷阱:如果你在组件顶层直接使用 $fetch(没有包裹在 useAsyncData 或 useFetch 中),并且该组件在服务端渲染,那么请求会在服务端执行。但当客户端激活(Hydration)时,同样的 **$fetch** **代码又会在客户端再执行一次,造成重复请求。
二、useAsyncData & useFetch:智能的双环境数据获取器
这两个组合函数是 Nuxt 数据获取的“智能大脑”。它们的关键特性是:“在服务端预取数据,并自动将数据序列化到客户端,避免重复请求”。
核心行为:
- 默认在服务端执行:在 SSR 模式下,当页面首次加载时,它们会在 Nuxt 服务器内部执行,获取数据并直接将数据嵌入到最终返回的 HTML 中。
- 在客户端激活:当 Vue 在客户端“激活”静态页面时,
useAsyncData和useFetch会识别到数据已经存在于从服务器传递过来的 payload 中,因此不会在客户端再次发起请求,而是直接使用已有的数据。 - 后续导航:当你在客户端通过导航跳转到另一个也使用了这些函数的页面时,它们会在客户端执行。
如何控制执行环境?
它们提供了一个 server 选项让你精确控制:
1 | // 默认:true - 在服务端执行(SSR 首屏) |
三、三者的对比总结
为了更直观地理解,下面的流程图展示了不同调用方式在 Nuxt 应用生命周期中的执行时机和数据流向:
这个图清晰地展示了:
**useFetch**/**useAsyncData**是贯穿服务端和客户端的“智能通道”,保证了数据的高效同步和无重复请求。- 直接使用** **
**$fetch**在组件顶层会导致重复请求,是需要避免的反模式。 - 在事件中使用的** **
**$fetch**是纯客户端行为。
最佳实践与选择指南
| 场景 | 推荐使用的工具 | 原因 |
|---|---|---|
| 获取页面组件所需数据 | **useFetch**** 或 ** **useAsyncData** |
自动处理 SSR/CSR,避免重复请求,数据序列化到客户端。 |
在事件处理、**onMounted**** **中获取数据 |
**$fetch** |
明确需要在客户端触发的请求。 |
| 在 API 路由或服务器中间件中 | **$fetch** |
明确的服务端环境,无需 useAsyncData的额外功能。 |
| 需要复杂的数据获取逻辑 | **useAsyncData**** + ** **$fetch** |
useAsyncData提供状态管理,内部函数可使用 $fetch进行复杂操作。 |
| 简单的 URL 请求 | **useFetch** |
最简洁的写法。 |
一句话总结:
- 用**
**useFetch**/**useAsyncData**来获取组件初始化时所需的数据**,让 Nuxt 智能决定执行环境。 - 用**
**$fetch**在明确的客户端交互或明确的服务端环境**中主动发起请求。
遵循这个原则,你就能高效且正确地在 Nuxt 应用中处理数据获取。
激活客户端需要开发手动调用什么api吗,服务端异步获取的数据注入到html这一步开发需要做什么?到客户端时如何获取数据呢?
这些问题触及了 Nuxt.js SSR 的核心魔法。好消息是,这个过程绝大部分是自动化的,开发者几乎不需要手动干预。Nuxt 和 Vue 底层已经为你处理好了一切。
下面我来逐一解答你的问题,你会看到 Nuxt 的设计是多么巧妙。
一、激活客户端需要开发手动调用什么 API 吗?
答:完全不需要。这是 Vue 和 Nuxt 自动完成的。
这个过程称为 Hydration(混合)。它的流程是:
- 自动执行:当浏览器加载完 Nuxt 发送过来的 HTML 和客户端 JavaScript 包后,Vue 会自动启动。
- 自动匹配:Vue 会将它的虚拟 DOM 与服务器渲染好的、已经存在的静态 HTML 结构进行对比和匹配。
- 自动“激活”:Vue 不会重新创建 DOM 元素,而是会将事件监听器、响应式数据系统等“附加”到这些现有的 DOM 元素上,使静态页面瞬间变为一个完全交互式的 Vue 应用。
作为开发者,你唯一要做的就是:
- 确保你的代码是同构的(即同一份代码既能在 Node.js 环境运行,也能在浏览器环境运行)。
- 避免在
created或setup等生命周期中使用浏览器特有的 API(如window,document),或者使用onMounted(仅在客户端执行)来包裹它们。
你不用写任何像** **app.hydrate()** **这样的代码,一切都是开箱即用、自动发生的。
二、服务端异步获取的数据注入到 HTML 这一步开发需要做什么?
答:你只需要使用正确的 API(**useAsyncData**** 或 **useFetch**),Nuxt 就会自动完成注入。**
这个“注入”过程在 Nuxt 中被称为 State Serialization(状态序列化) 或 ** dehydration(脱水)**。
你的工作(非常简单):
- **使用
**useAsyncData**或 ****useFetch**:在你的页面组件中,用它们来获取数据。
1 | <script setup> |
- Nuxt 自动完成后续所有事情:
- Nuxt 在服务端执行完
useFetch后,会自动将posts数据序列化为 JSON 字符串。 - 将这个 JSON 字符串自动嵌入到最终 HTML 的
<head>部分的一个<script>标签中。 - 这个标签的内容通常是
window.__NUXT__ = { ... },其中就包含了所有页面的预取数据。
- Nuxt 在服务端执行完
你不需要手动操作 DOM 去注入数据,Nuxt 的渲染引擎为你包办了一切。
三、到客户端时如何获取数据呢?
答:客户端 Vue 应用会自动从** **window.__NUXT__** **中提取并复用数据,无需再次请求。
这个过程是 State Deserialization(状态反序列化) 或 rehydration(补水)。
它的自动流程如下:
- 数据随 HTML 到达浏览器:HTML 中的
<script>window.__NUXT__ = {...}</script>会先被执行,将数据挂载到全局对象上。 - 客户端 Vue 应用启动:客户端的 JavaScript 包加载完毕后,Vue 和 Nuxt 开始初始化。
- 自动提取数据:当客户端的
useFetch('/api/posts')代码执行时,它不会真正去发起网络请求,而是会先自动去****window.__NUXT__****对象里查找,看是否存在服务端已经为它准备好的数据。 - 直接复用数据:如果找到了,它就直接使用这份数据,完全跳过网络请求。这样就保证了客户端和服务端的数据状态绝对一致,这也是 Hydration 能成功的前提。
你可以通过 **useNuxtData** 这个工具函数来验证和访问这些被缓存的数据:
1 | <script setup> |
服务端将预取数据潜入到script标签中并挂载到window上,那么预取数据是不是不能包含用户登录等敏感信息,否则不安全?
你这个问题问得非常非常关键,切中了SSR安全的核心!你的直觉完全正确。
绝对不应该将任何敏感信息(如用户凭证、Token、个人身份信息PII等)内联到HTML的** **<script>** 标签中,并通过 **window.__NUXT__** **暴露给客户端。
这样做会带来严重的安全风险:
- 数据泄露:任何能打开浏览器开发者工具的人,都可以直接看到
window.__NUXT__里的全部内容。 - XSS攻击加剧:如果你的应用存在XSS(跨站脚本)漏洞,攻击者可以更容易地编写脚本窃取
window.__NUXT__中的所有数据,而不必费力去窃取多个API请求的返回结果。 - 缓存风险:HTML页面可能会被CDN、代理服务器或浏览器缓存。如果其中包含了用户敏感信息,就意味着这些信息也可能被缓存并泄露给其他用户。
那么,如何处理需要认证的敏感数据?
正确的做法是将敏感数据与非敏感数据分离,并遵循“按需索取”和“最小化暴露”的原则。以下是几种安全策略:
策略一:敏感数据绝不预取,仅在客户端获取
这是最常用、最安全的策略。用户登录状态、个人资料等高度敏感的数据,不应该在服务端的 useFetch/useAsyncData 中获取。
1 | <script setup> |
策略二:使用 useState 进行状态管理,区分服务端与客户端状态
你可以利用 useState 的灵活性来管理不同环境的状态。
1 | <script setup> |
策略三:API 设计分离 - 提供公开和私密端点
从后端设计上就进行分离:
/api/public/data:返回不敏感的数据,可以安全地在服务端渲染。/api/private/user-data:返回敏感数据,必须认证且在客户端获取。
Nuxt 如何安全地处理认证?
认证的最佳实践是使用 HttpOnly Cookies 来传输令牌(Token),而不是通过 window.__NUXT__ 或 JS 可读的 Cookie。
- 登录流程:
- 用户提交登录表单,客户端
$fetch发送到/api/auth/login。 - 后端验证成功后,设置一个 HttpOnly、Secure、SameSite=Strict 的 Cookie(包含认证Token)。这个 Cookie 对 JavaScript 不可见,极大地增强了安全性。
- 前端只需知道登录成功,无需接触 Token 本身。
- 用户提交登录表单,客户端
- 获取用户数据:
- 在客户端,调用
$fetch('/api/me')。 - 浏览器会自动在请求中带上 HttpOnly Cookie。
- 后端验证 Cookie 中的 Token 有效性后,返回对应用户的数据。
- 在客户端,调用
- 服务端渲染中的认证:
- 如果服务端需要根据用户状态渲染不同内容(例如“您好,用户名”),可以通过服务器中间件或 API 路由来处理。
- 服务端可以读取请求中的 Cookie,去后端验证用户身份,然后决定返回什么数据。但这个验证过程发生在后端,结果信息需要是非敏感的(例如只返回
username,而不是返回token或email)。
1 | <script setup> |
总结
- 核心原则:绝不将敏感数据内联到 HTML 中。
window.__NUXT__应该是“公开的”或“非敏感的”。 - 数据分离:将数据分为“公开”和“私密”两类。公开数据用
useFetch服务端预取;私密数据在客户端用$fetch按需获取。 - 认证最佳实践:使用 HttpOnly Cookies 来安全地传输认证凭证,而不是将其暴露给客户端 JavaScript 或
window对象。 - 信任后端:敏感的权限检查和数据处理逻辑应该始终放在后端 API 中。前端(包括SSR服务端)只负责展示非敏感的结果。
你的安全意识非常到位,遵循这些原则可以让你构建出既高效又安全的 Nuxt.js 应用。
除此之外,服务端渲染还有什么不能实现的呢?canvas?
说得非常对!Canvas 是一个绝佳的例子,它完美地揭示了服务端渲染(SSR)的“盲区”。
SSR 的核心是生成静态的 HTML 和 CSS 字符串。因此,任何动态的、依赖于浏览器 JavaScript 运行时环境的功能,在纯 SSR 阶段都无法实现或功能不全。
除了 Canvas,还有很多类似的限制。我们可以将它们分为几大类:
一、浏览器特有的 API 和全局对象
这是最直接的一类。在 Node.js 服务器环境中,根本没有 window, document, navigator 等对象。
| API/功能 | 原因 | 解决方案 |
|---|---|---|
**window**、**document** |
Node.js 中不存在。 | 使用 onMounted钩子或 clientOnly组件确保只在客户端访问。 |
**alert**、**confirm**、**prompt** |
浏览器交互对话框。 | 逻辑移至客户端,或使用基于组件的替代品(如模态框)。 |
Canvas (**<canvas>**) / WebGL |
需要浏览器渲染上下文来绘图和操作像素。 | 只能在客户端初始化和使用。SSR 只能渲染一个空画布。 |
地理位置 (**navigator.geolocation**) |
需要用户的浏览器授权和设备硬件支持。 | 仅在客户端通过 onMounted或用户交互触发。 |
本地存储 (**localStorage**, **sessionStorage**, **IndexedDB**) |
是浏览器的持久化存储机制。 | 在 onMounted中访问,或使用 useLocalStorage等组合式函数(内部做了客户端检查)。 |
媒体设备 (**navigator.mediaDevices**) |
需要访问麦克风、摄像头等硬件。 | 完全的用户客户端行为。 |
二、依赖浏览器渲染或布局的功能
这类功能需要知道元素的真实尺寸和位置,而这些信息在纯字符串的 SSR 阶段是无法获得的。
| 功能 | 原因 | 解决方案 |
|---|---|---|
元素尺寸/位置 (如 element.offsetWidth, getBoundingClientRect()) |
SSR 只有 HTML 字符串,没有真实的布局和渲染。 | 在 onMounted后使用,或使用 Vue 的 nextTick确保 DOM 已更新。 |
| 基于尺寸的渲染 (如图表库 ECharts、D3.js) | 需要挂载到真实 DOM 元素并获取其宽高才能渲染。 | 在 onMounted中初始化图表实例。 |
| 动画 (CSS 动画除外) | 许多 JS 动画库需要操作 DOM 样式。 | 使用 onMounted启动动画,或使用 CSS 动画(SSR 支持)。 |
三、用户交互和状态
SSR 输出的是一个“快照”,无法预知用户未来的行为。
| 功能 | 原因 | 解决方案 |
|---|---|---|
| 用户输入 (表单输入、焦点状态) | SSR 无法预知用户会输入什么。 | SSR 可以渲染表单结构,但交互和值绑定必须在客户端完成。 |
| 鼠标事件、键盘事件 | 纯静态环境,无用户交互。 | 完全由客户端 JavaScript 处理。 |
浏览器标签页可见性 (document.visibilityState) |
依赖于用户当前的浏览器状态。 | 纯客户端逻辑。 |
四、第三方库
许多强大的第三方库在设计时就是为浏览器而生的。
| 库类型 | 问题 | 解决方案 |
|---|---|---|
| 地图库 (如 Leaflet, Google Maps) | 需要挂载到 DOM 并初始化地图渲染上下文。 | 使用 onMounted初始化,或使用 Nuxt 模块(如 nuxt-leaflet)。 |
| 可视化库 (如 D3, Three.js) | 严重依赖 Canvas、WebGL 或 SVG 操作。 | 只能在客户端运行。 |
| 分析/广告库 (如 Google Analytics) | 依赖 window对象和浏览器环境来跟踪用户。 |
使用 Nuxt 插件(client: true选项)或直接在 onMounted中加载。 |
如何安全地处理这些限制?Nuxt 提供的解决方案
Nuxt 提供了一系列模式来优雅地解决这些问题:
1. onMounted 钩子 (最常用)
确保代码只在客户端执行。
1 | <script setup> |
2. 条件渲染与 <ClientOnly> 组件
防止不支持 SSR 的组件在服务器端渲染时出错。
1 | <template> |
3. 使用 process.client 标志进行运行时检查
1 | <script setup> |
4. 为第三方库创建客户端插件
1 | // plugins/analytics.client.js - 注意 .client 后缀 |
总结
服务端渲染 (SSR) 的本质是静态化,它擅长的是:
- 生成初始 HTML 内容
- 提供更好的 SEO
- 提升首屏加载性能
而动态交互和浏览器依赖永远是 SSR 的盲区,必须交给客户端处理。
因此,一个成熟的 Nuxt 应用是两者结合的“混合体”:
- 服务端:生成静态结构和首屏内容。
- 客户端:“激活”页面,接管所有交互,并加载那些依赖浏览器环境的动态功能。
你的工作就是清晰地界定哪些逻辑属于服务端,哪些属于客户端,并使用 Nuxt 提供的模式(onMounted, <ClientOnly>, .client 插件)将它们优雅地结合起来。
nuxt中,客户端激活后,发起请求nuxt的中间件,会有跨域问题吗?
这是一个非常好的问题,它触及了 Nuxt 全栈架构的核心优势。
简单而直接的答案是:不会。在客户端激活后,向同源的 Nuxt 中间件或 API 路由发起请求,绝对不会产生跨域问题。
这是因为你发起请求的目标和你的页面来源是完全同源的。
为什么不会跨域?—— 同源策略详解
让我们回顾一下“同源策略”:当协议、域名、端口都相同时,即为同源,浏览器允许请求。
假设你的 Nuxt 应用部署在:https://www.my-app.com
- 你的页面来源:
浏览器中显示的地址是:https://www.my-app.com/some-page - 你请求的目标:
你在代码中发起的请求是:
1 | // 使用相对路径,目标自动补全为:https://www.my-app.com/api/hello |
- 对比:
- 协议:都是
https - 域名:都是
www.my-app.com - 端口:都是
443(HTTPS 默认端口)
- 协议:都是
结论:完全同源,浏览器欣然放行,没有任何跨域限制。
Nuxt 如何处理这些请求?—— 请求生命周期
理解这个过程能让你更清楚为什么这是安全的:
如图所示,无论是开发还是生产环境,你的 API 请求和前端页面都由同一个主机处理。它们处于同一个“生态系统”内,通信是内部的、安全的,不存在跨域问题。
什么情况下会有跨域问题?
只有当你的页面来源和请求目标不同源时,才会触发跨域。例如:
| 你的页面在 | 你请求的目标 | 是否跨域 | 原因 |
|---|---|---|---|
https://www.my-app.com |
https://www.my-app.com/api/hello |
否 | 同源 |
https://www.my-app.com |
https://api.my-app.com |
是 | 子域名不同 (www vs api) |
http://localhost:3000 |
https://api.third-party.com |
是 | 完全不同的域名 |
https://www.my-app.com |
http://www.my-app.com/api/hello |
是 | 协议不同 (httpsvs http) |
对于最后一种情况(生产环境前后端分离),解决方案是:
- 后端配置 CORS:在你的
api.my-app.com服务器上设置Access-Control-Allow-Origin: https://www.my-app.com响应头。 - 使用反向代理:配置你的生产服务器(如 Nginx),将对
/api/的请求代理到api.my-app.com,让浏览器始终觉得是在请求同源地址。这是更推荐的做法。
总结
- 在 Nuxt 应用中,请求自身的 API 路由 (
**/api/xxx**) 或服务器中间件是绝对同源的,没有跨域问题。 - 这是 Nuxt 全栈框架的巨大优势之一,它简化了开发,让你无需在开发阶段为 CORS 烦恼。
- 跨域问题只会在你请求外部第三方 API 且对方未正确配置 CORS 时出现。
- 如果你的生产环境是前后端完全分离的(不同域),那么需要在生产环境的后端配置 CORS 或通过反向代理来解决。
所以,请放心地在你的 Nuxt 应用内部调用 API,这是最安全、最正确的做法。
那如果对后端接口(另一台服务器上)的请求都由nuxt中间件转发,是不是就不需要处理客户端请求后端接口的跨域问题了?开发环境不需要配代理,生产环境也不需要配反向代理和cors了?
你的这个思路非常棒,完全正确! 这正是构建现代 Web 应用的一种核心架构模式,被称为 “BFF(Backend For Frontend)模式” 或 “API 网关模式”。
你的推理链条是:
- 所有客户端请求都只发往同源的 Nuxt 服务器(
/api/proxy)。 - Nuxt 服务器上的中间件接收到请求后,代为转发给真正的后端服务器。
- 由于服务器之间通信(Nuxt Server -> Your Backend Server)没有跨域限制,所以问题迎刃而解。
这个方案在理论上是完全可行且非常优雅的,它确实可以让你完全摆脱 CORS 的困扰。
这种架构的详细工作流程
如图所示,浏览器始终只与 my-nuxt-app.com 通信,完美符合同源策略。
优缺点分析:这是否是“万能药”?
虽然这个方案能根治跨域,但它也引入了一些新的考虑因素:
优点 ✅
- 彻底解决 CORS:前端开发者完全无需再关心跨域配置,开发体验极其流畅。
- 隐藏后端架构:真正的后端地址、端口、API 结构对客户端完全隐藏,更安全。
- 协议转换:可以轻松地在 Nuxt 中处理 HTTPS -> HTTP 的请求(服务器间通信允许)。
- 数据处理与聚合:你可以在 Nuxt 中间件中对多个后端服务的返回值进行聚合、过滤、转换,为前端提供最合适的数据结构,减少前端请求次数。
缺点与需要考虑的因素 ⚠️
- 额外的网络跳转:所有请求都多经过一环(浏览器 -> Nuxt -> 真实后端),会增加微小的延迟。对于延迟敏感的应用需要优化。
- 单点压力与故障点:Nuxt 服务器现在成为了所有 API 流量的入口。如果它宕机,所有请求都会失败。需要保证其高可用性。
- 复杂性转移:虽然前端变简单了,但 Nuxt 层(BFF 层)的逻辑变复杂了。你需要在这里编写转发、错误处理、认证等逻辑。
- 认证问题:如果后端 API 需要认证,你需要决定如何传递认证信息。
- 方案A(推荐):浏览器将认证 Token 发给 Nuxt,Nuxt 再原样转发给后端。
- 方案B:Nuxt 服务器自己持有访问后端的凭证,替用户与后端通信。但这需要非常小心地管理权限。
如何实现?
在 Nuxt 中,你通常使用 API 路由 或 服务器中间件 来实现,而不是普通的中间件,因为它们专门处理服务器逻辑。
示例:在 **server/api/proxy/[...].ts** 中创建一个捕获所有路由的 API
1 | // server/api/proxy/[...].ts |
这样,前端所有发往 /api/proxy/items、/api/proxy/user/profile 的请求,都会被这个 handler 捕获,并转发到 https://your-real-backend.com/api/items 和 https://your-real-backend.com/api/user/profile。
结论
是的,你的想法是完全正确且高效的。通过让 Nuxt 服务器作为所有后端请求的代理,你可以一劳永逸地解决跨域问题,无需在开发或生产环境配置任何 CORS 或代理规则。
这不仅是解决跨域的手段,更是一种先进的架构设计选择(BFF)。它特别适用于:
- 中大型前后端分离项目。
- 需要集成多个后端微服务的复杂前端。
- 希望简化前端开发流程,将复杂性集中到 BFF 层的团队。
你只需要评估其带来的额外延迟和单点压力是否在你的应用可接受范围内即可。对于绝大多数应用来说,这个方案的利远大于弊。
- Title: Nuxt
- Author: cenweilings@163.com
- Created at : 2025-08-14 16:00:00
- Updated at : 2025-09-14 13:36:42
- Link: https://blog-git-main-cenweilings-projects.vercel.app/2025/08/14/Nuxt.js/
- License: This work is licensed under CC BY-NC-SA 4.0.